
 Nanjing University of Science and Technology
Nanjing University of Science and TechnologyI ranked first in comprehensive evaluation for two consecutive years. As first author, I published 1 paper at a CCF-A conference and 2 at B-level conferences, and served as a reviewer for top venues including IJCAI and NeurIPS. I hold 2 utility model patents and 1 design patent, and have received several international/national-level awards. I scored 637 on CET-6, 7.0 on IELTS, and passed University German Level 4.
Research InterestDeep learning, AI safety, Embodied AI, Computer vision
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
Nanjing University of Science and TechnologySchool of Design Art and Media
Undergraduate2022.09 - present
Experience
-
 Peking UniversityInternJan. 2025 - present
Peking UniversityInternJan. 2025 - present -
 Zayed UniversityResearch AssistantMay 2025 - present
Zayed UniversityResearch AssistantMay 2025 - present
Honors & Awards
-
American MCM/ICM 1st Prize2022
-
APMCM 2nd Prize2022/2023
-
NECCS 1st Prize2023
-
ROBOCON 1st Prize2024
-
Midwest Foreign Language Translation Contest 1st Prize2024
-
China Creative Challenges Contest 2nd Prize2024
-
New Liberal Arts Innovation Competition 2nd Prize2024
-
Internet + 1st/2nd Prize2024
-
CUIDC 1st Prize2024
Service
-
2025 IJCAI Main TrackPC member
-
2025 IJCNN Main TrackReviewer
-
2024 NeurIPS Workshop (SafeGenAi/Compression/FM4Science)Reviewer
-
2024 ICWSM Main TrackReviewer
-
Neurocomputing (SCI-II)Reviewer
-
Applied Intelligence (SCI-II)Reviewer
-
Pattern Recognition Letters (SCI-III)Reviewer
News
Selected Publications (view all )
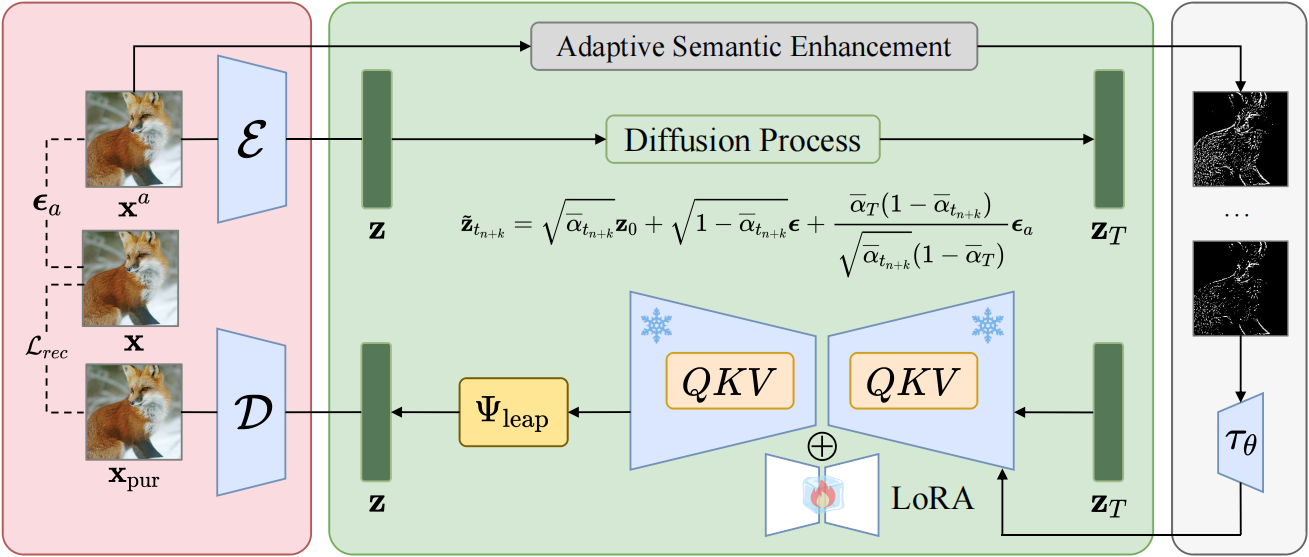
DBLP: Noise Bridge Consistency Distillation For Efficient And Reliable Adversarial Purification
Chihan Huang, Belal Alsinglawi, Islam Al-qudah
Under Review 2025
Recent advances in deep neural networks (DNNs) have led to remarkable success across a wide range of tasks. However, their susceptibility to adversarial perturbations remains a critical vulnerability. Existing diffusion-based adversarial purification methods often require intensive iterative denoising, severely limiting their practical deployment. In this paper, we propose Diffusion Bridge Distillation for Purification (DBLP), a novel and efficient diffusion-based framework for adversarial purification. Central to our approach is a new objective, noise bridge distillation, which constructs a principled alignment between the adversarial noise distribution and the clean data distribution within a latent consistency model (LCM). To further enhance semantic fidelity, we introduce adaptive semantic enhancement, which fuses multi-scale pyramid edge maps as conditioning input to guide the purification process. Extensive experiments across multiple datasets demonstrate that DBLP achieves state-of-the-art (SOTA) robust accuracy, superior image quality, and around 0.2s inference time, marking a significant step toward real-time adversarial purification.
DBLP: Noise Bridge Consistency Distillation For Efficient And Reliable Adversarial Purification
Chihan Huang, Belal Alsinglawi, Islam Al-qudah
Under Review 2025
Recent advances in deep neural networks (DNNs) have led to remarkable success across a wide range of tasks. However, their susceptibility to adversarial perturbations remains a critical vulnerability. Existing diffusion-based adversarial purification methods often require intensive iterative denoising, severely limiting their practical deployment. In this paper, we propose Diffusion Bridge Distillation for Purification (DBLP), a novel and efficient diffusion-based framework for adversarial purification. Central to our approach is a new objective, noise bridge distillation, which constructs a principled alignment between the adversarial noise distribution and the clean data distribution within a latent consistency model (LCM). To further enhance semantic fidelity, we introduce adaptive semantic enhancement, which fuses multi-scale pyramid edge maps as conditioning input to guide the purification process. Extensive experiments across multiple datasets demonstrate that DBLP achieves state-of-the-art (SOTA) robust accuracy, superior image quality, and around 0.2s inference time, marking a significant step toward real-time adversarial purification.

ScoreAdv: Score-based Targeted Generation of Natural Adverarial Examples via Diffusion Models
Chihan Huang, Hao Tang
Under Review 2025
Despite the remarkable success of deep learning across various domains, these models remain vulnerable to adversarial attacks. Although many existing adversarial attack methods achieve high success rates, they typically rely on $\ell_{p}$-norm perturbation constraints, which do not align with human perceptual capabilities. Consequently, researchers have shifted their focus toward generating natural, unrestricted adversarial examples (UAEs). Traditional approaches using GANs suffer from inherent limitations, such as poor image quality due to the instability and mode collapse of GANs. Meanwhile, diffusion models have been employed for UAE generation, but they still predominantly rely on iterative PGD perturbation injection, without fully leveraging the denoising capabilities that are central to the diffusion model. In this paper, we introduce a novel approach for generating UAEs based on diffusion models, named ScoreAdv. This method incorporates an interpretable adversarial guidance mechanism to gradually shift the sampling distribution towards the adversarial distribution, while using an interpretable saliency map technique to inject the visual information of a reference image into the generated samples. Notably, our method is capable of generating an unlimited number of natural adversarial examples and can attack not only image classification models but also image recognition and retrieval models. We conduct extensive experiments on the ImageNet and CelebA datasets, validating the performance of ScoreAdv across ten target models in both black-box and white-box settings. Our results demonstrate that ScoreAdv achieves state-of-the-art attack success rates and image quality. Furthermore, due to the dynamic interplay between denoising and adding adversarial perturbation in the diffusion model, ScoreAdv maintains high performance even when confronted with defense mechanisms, showcasing its robustness.
ScoreAdv: Score-based Targeted Generation of Natural Adverarial Examples via Diffusion Models
Chihan Huang, Hao Tang
Under Review 2025
Despite the remarkable success of deep learning across various domains, these models remain vulnerable to adversarial attacks. Although many existing adversarial attack methods achieve high success rates, they typically rely on $\ell_{p}$-norm perturbation constraints, which do not align with human perceptual capabilities. Consequently, researchers have shifted their focus toward generating natural, unrestricted adversarial examples (UAEs). Traditional approaches using GANs suffer from inherent limitations, such as poor image quality due to the instability and mode collapse of GANs. Meanwhile, diffusion models have been employed for UAE generation, but they still predominantly rely on iterative PGD perturbation injection, without fully leveraging the denoising capabilities that are central to the diffusion model. In this paper, we introduce a novel approach for generating UAEs based on diffusion models, named ScoreAdv. This method incorporates an interpretable adversarial guidance mechanism to gradually shift the sampling distribution towards the adversarial distribution, while using an interpretable saliency map technique to inject the visual information of a reference image into the generated samples. Notably, our method is capable of generating an unlimited number of natural adversarial examples and can attack not only image classification models but also image recognition and retrieval models. We conduct extensive experiments on the ImageNet and CelebA datasets, validating the performance of ScoreAdv across ten target models in both black-box and white-box settings. Our results demonstrate that ScoreAdv achieves state-of-the-art attack success rates and image quality. Furthermore, due to the dynamic interplay between denoising and adding adversarial perturbation in the diffusion model, ScoreAdv maintains high performance even when confronted with defense mechanisms, showcasing its robustness.

CtrlDiff: Boosting Large Diffusion Language Models with Dynamic Block Prediction and Controllable Generation
Chihan Huang, Hao Tang
Under Review 2025
Although autoregressive models have dominated language modeling in recent years, there has been a growing interest in exploring alternative paradigms to the conventional next-token prediction framework. Diffusion-based language models have emerged as a compelling alternative due to their powerful parallel generation capabilities and inherent editability. However, these models are often constrained by fixed-length generation. A promising direction is to combine the strengths of both paradigms, segmenting sequences into blocks, modeling autoregressive dependencies across blocks while leveraging discrete diffusion to estimate the conditional distribution within each block given the preceding context. Nevertheless, their practical application is often hindered by two key limitations: rigid fixed-length outputs and a lack of flexible control mechanisms. In this work, we address the critical limitations of fixed granularity and weak controllability in current large diffusion language models. We propose CtrlDiff, a dynamic and controllable semi-autoregressive framework that adaptively determines the size of each generation block based on local semantics using reinforcement learning. Furthermore, we introduce a classifier-guided control mechanism tailored to discrete diffusion, which significantly reduces computational overhead while facilitating efficient post-hoc conditioning without retraining. Extensive experiments demonstrate that CtrlDiff sets a new standard among hybrid diffusion models, narrows the performance gap to state-of-the-art autoregressive approaches, and enables effective conditional text generation across diverse tasks.
CtrlDiff: Boosting Large Diffusion Language Models with Dynamic Block Prediction and Controllable Generation
Chihan Huang, Hao Tang
Under Review 2025
Although autoregressive models have dominated language modeling in recent years, there has been a growing interest in exploring alternative paradigms to the conventional next-token prediction framework. Diffusion-based language models have emerged as a compelling alternative due to their powerful parallel generation capabilities and inherent editability. However, these models are often constrained by fixed-length generation. A promising direction is to combine the strengths of both paradigms, segmenting sequences into blocks, modeling autoregressive dependencies across blocks while leveraging discrete diffusion to estimate the conditional distribution within each block given the preceding context. Nevertheless, their practical application is often hindered by two key limitations: rigid fixed-length outputs and a lack of flexible control mechanisms. In this work, we address the critical limitations of fixed granularity and weak controllability in current large diffusion language models. We propose CtrlDiff, a dynamic and controllable semi-autoregressive framework that adaptively determines the size of each generation block based on local semantics using reinforcement learning. Furthermore, we introduce a classifier-guided control mechanism tailored to discrete diffusion, which significantly reduces computational overhead while facilitating efficient post-hoc conditioning without retraining. Extensive experiments demonstrate that CtrlDiff sets a new standard among hybrid diffusion models, narrows the performance gap to state-of-the-art autoregressive approaches, and enables effective conditional text generation across diverse tasks.
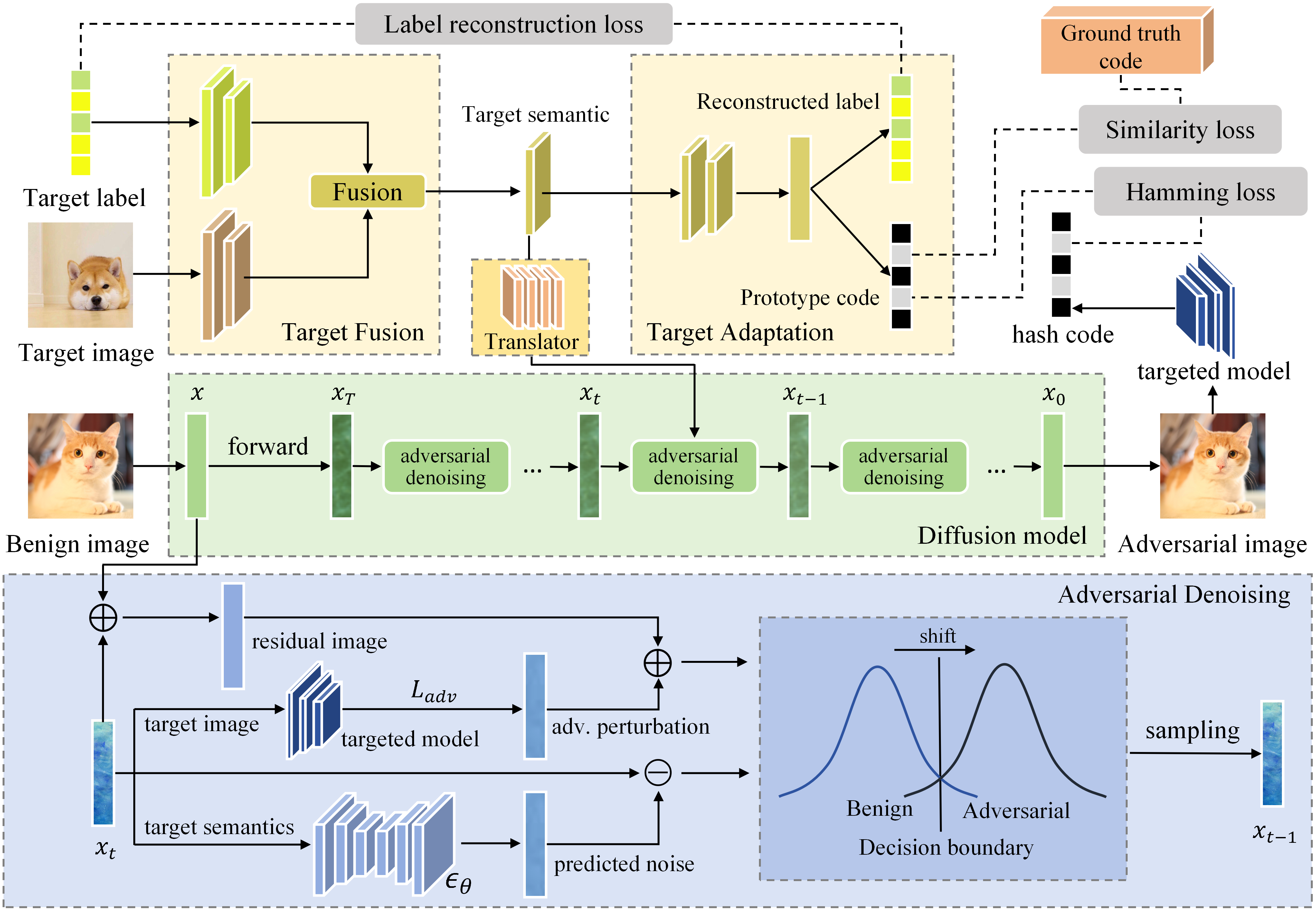
HUANG: A Robust Diffusion Model-based Targeted Adversarial Attack Against Deep Hashing Retrieval
Chihan Huang, Xiaobo Shen
AAAI Conference on Artificial Intelligence (AAAI) 2025 Poster
Deep hashing models have achieved great success in retrieval tasks due to their powerful representation and strong information compression capabilities. However, they inherit the vulnerability of deep neural networks to adversarial perturbations. Attackers can severely impact the retrieval capability of hashing models by adding subtle, carefully crafted adversarial perturbations to benign images, transforming them into adversarial images. Most existing adversarial attacks target image classification models, with few focusing on retrieval models. We propose HUANG, the first targeted adversarial attack algorithm to leverage a diffusion model for hashing retrieval in black-box scenarios. In our approach, adversarial denoising uses adversarial perturbations and residual image to guide the shift from benign to adversarial distribution. Extensive experiments demonstrate the superiority of HUANG across different datasets, achieving state-of-the-art performance in black-box targeted attacks. Additionally, the dynamic interplay between denoising and adding adversarial perturbations in adversarial denoising endows HUANG with exceptional robustness and transferability.
HUANG: A Robust Diffusion Model-based Targeted Adversarial Attack Against Deep Hashing Retrieval
Chihan Huang, Xiaobo Shen
AAAI Conference on Artificial Intelligence (AAAI) 2025 Poster
Deep hashing models have achieved great success in retrieval tasks due to their powerful representation and strong information compression capabilities. However, they inherit the vulnerability of deep neural networks to adversarial perturbations. Attackers can severely impact the retrieval capability of hashing models by adding subtle, carefully crafted adversarial perturbations to benign images, transforming them into adversarial images. Most existing adversarial attacks target image classification models, with few focusing on retrieval models. We propose HUANG, the first targeted adversarial attack algorithm to leverage a diffusion model for hashing retrieval in black-box scenarios. In our approach, adversarial denoising uses adversarial perturbations and residual image to guide the shift from benign to adversarial distribution. Extensive experiments demonstrate the superiority of HUANG across different datasets, achieving state-of-the-art performance in black-box targeted attacks. Additionally, the dynamic interplay between denoising and adding adversarial perturbations in adversarial denoising endows HUANG with exceptional robustness and transferability.
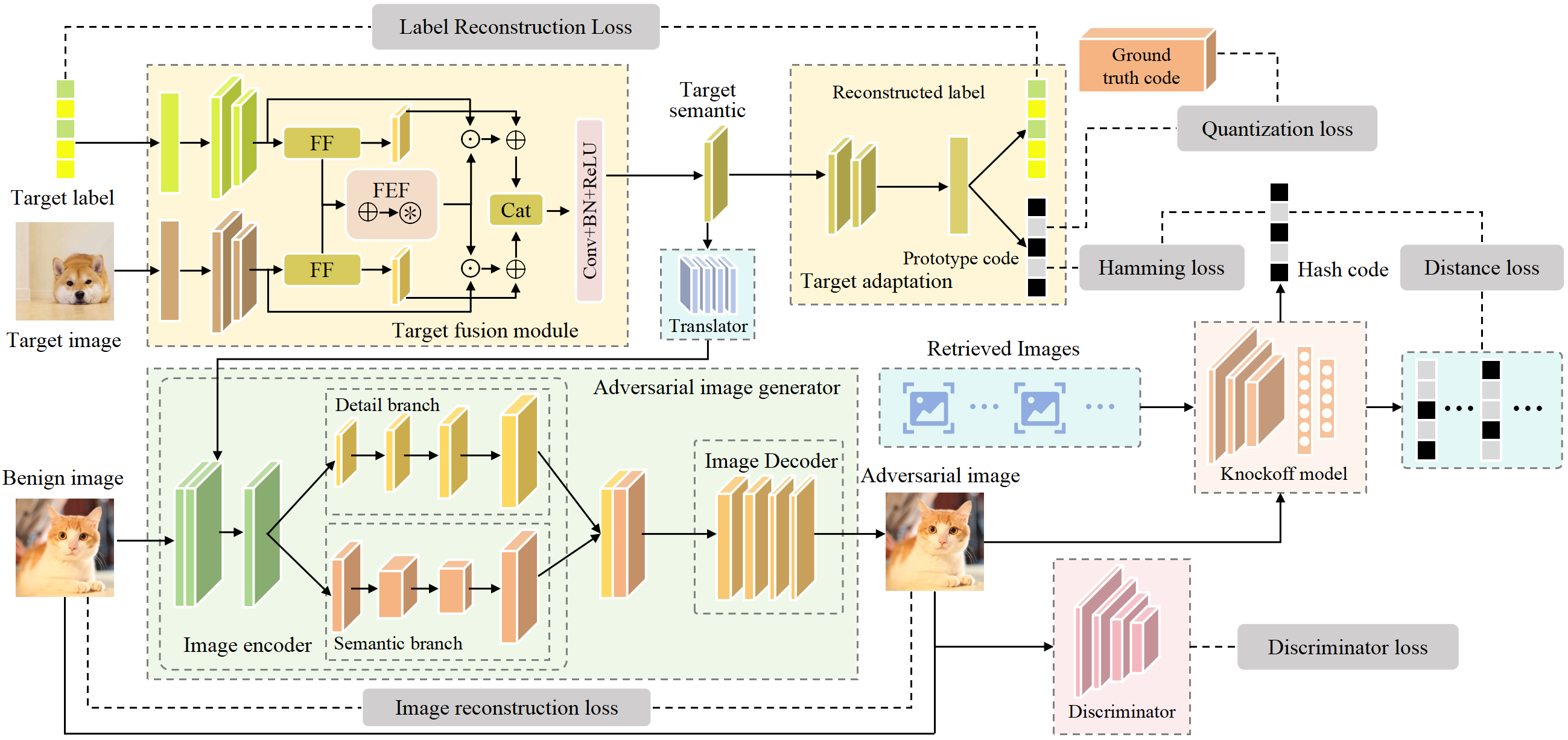
Efficient Multi-branch Black-box Semantic-aware Targeted Attack Against Deep Hashing Retrieval
Chihan Huang, Xiaobo Shen
International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2025 Poster
Deep hashing have achieved exceptional performance in retrieval tasks due to their robust representational capabilities. However, they inherit the vulnerability of deep neural networks to adversarial attacks. These models are susceptible to finely crafted adversarial perturbations that can lead them to return incorrect retrieval results. Although numerous adversarial attack methods have been proposed, there has been a scarcity of research focusing on targeted black-box attacks against deep hashing models. We introduce the Efficient Multi-branch Black-box Semantic-aware Targeted Attack against Deep Hashing Retrieval (EmbSTar), capable of executing targeted black-box attacks on hashing models. Initially, we distill the target model to create a knockoff model. Subsequently, we devised novel Target Fusion and Target Adaptation modules to integrate and enhance the semantic information of the target label and image. Knockoff model is then utilized to align the adversarial image more closely with the target image semantically. With the knockoff model, we can obtain powerful targeted attacks with few queries. Extensive experiments demonstrate that EmbSTar significantly surpasses previous models in its targeted attack capabilities, achieving SOTA performance for targeted black-box attacks.
Efficient Multi-branch Black-box Semantic-aware Targeted Attack Against Deep Hashing Retrieval
Chihan Huang, Xiaobo Shen
International Conference on Acoustics, Speech and Signal Processing (ICASSP) 2025 Poster
Deep hashing have achieved exceptional performance in retrieval tasks due to their robust representational capabilities. However, they inherit the vulnerability of deep neural networks to adversarial attacks. These models are susceptible to finely crafted adversarial perturbations that can lead them to return incorrect retrieval results. Although numerous adversarial attack methods have been proposed, there has been a scarcity of research focusing on targeted black-box attacks against deep hashing models. We introduce the Efficient Multi-branch Black-box Semantic-aware Targeted Attack against Deep Hashing Retrieval (EmbSTar), capable of executing targeted black-box attacks on hashing models. Initially, we distill the target model to create a knockoff model. Subsequently, we devised novel Target Fusion and Target Adaptation modules to integrate and enhance the semantic information of the target label and image. Knockoff model is then utilized to align the adversarial image more closely with the target image semantically. With the knockoff model, we can obtain powerful targeted attacks with few queries. Extensive experiments demonstrate that EmbSTar significantly surpasses previous models in its targeted attack capabilities, achieving SOTA performance for targeted black-box attacks.
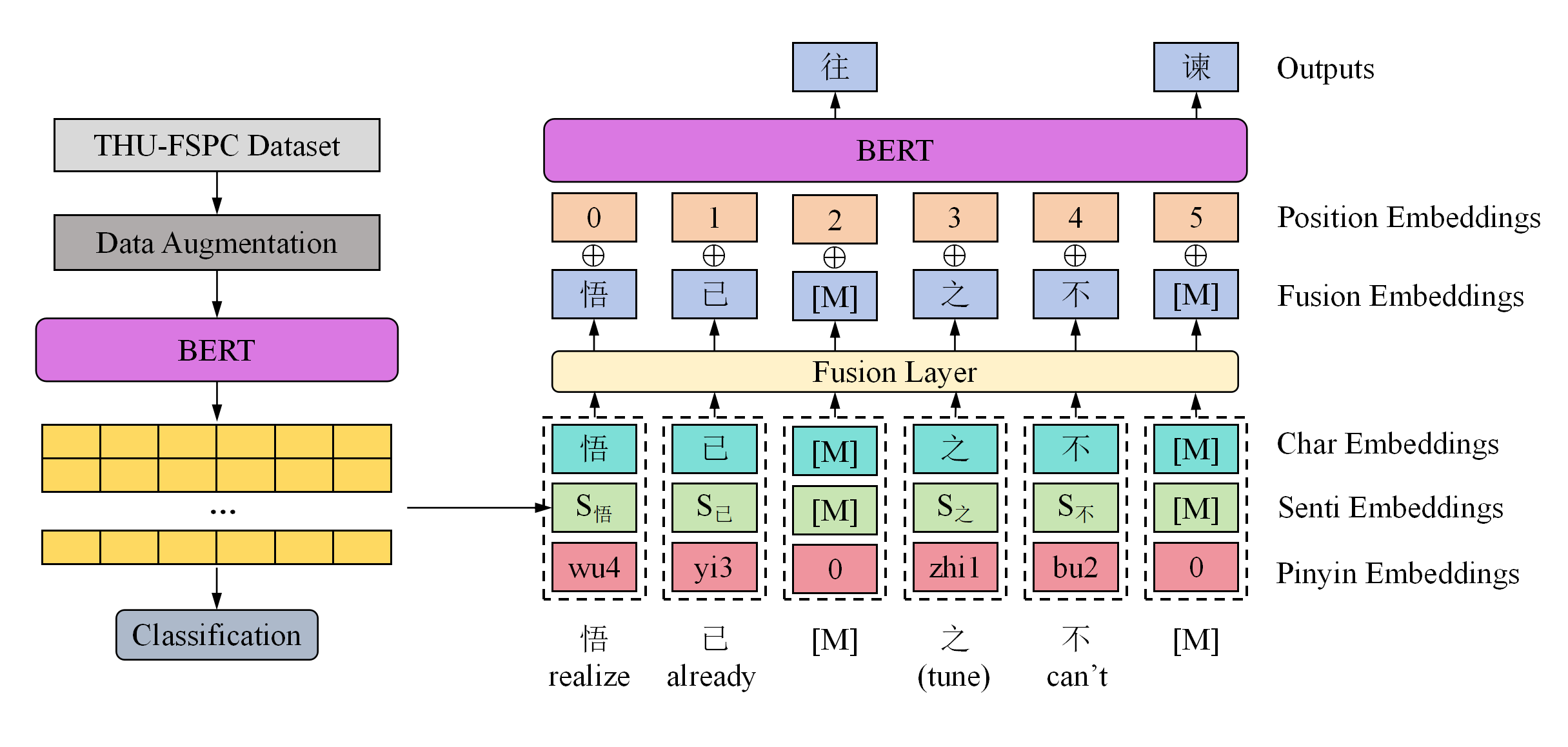
PoemBERT: A Dynamic Masking Content and Ratio Based Semantic Language Model For Chinese Poem Generation
Chihan Huang, Xiaobo Shen
International Conference on Computational Linguistics (COLING) 2025 Poster
Ancient Chinese poetry stands as a crucial treasure in Chinese culture. To address the absence of pre-trained models for ancient poetry, we introduced PoemBERT, a BERT-based model utilizing a corpus of classical Chinese poetry. Recognizing the unique emotional depth and linguistic precision of poetry, we incorporated sentiment and pinyin embeddings into the model, enhancing its sensitivity to emotional information and addressing challenges posed by the phenomenon of multiple pronunciations for the same Chinese character. Additionally, we proposed Character Importance-based masking and dynamic masking strategies, significantly augmenting the model's capability to extract imagery-related features and handle poetry-specific information. Fine-tuning our PoemBERT model on various downstream tasks, including poem generation and sentiment classification, resulted in state-of-the-art performance in both automatic and manual evaluations. We provided explanations for the selection of the dynamic masking rate strategy and proposed a solution to the issue of a small dataset size.
PoemBERT: A Dynamic Masking Content and Ratio Based Semantic Language Model For Chinese Poem Generation
Chihan Huang, Xiaobo Shen
International Conference on Computational Linguistics (COLING) 2025 Poster
Ancient Chinese poetry stands as a crucial treasure in Chinese culture. To address the absence of pre-trained models for ancient poetry, we introduced PoemBERT, a BERT-based model utilizing a corpus of classical Chinese poetry. Recognizing the unique emotional depth and linguistic precision of poetry, we incorporated sentiment and pinyin embeddings into the model, enhancing its sensitivity to emotional information and addressing challenges posed by the phenomenon of multiple pronunciations for the same Chinese character. Additionally, we proposed Character Importance-based masking and dynamic masking strategies, significantly augmenting the model's capability to extract imagery-related features and handle poetry-specific information. Fine-tuning our PoemBERT model on various downstream tasks, including poem generation and sentiment classification, resulted in state-of-the-art performance in both automatic and manual evaluations. We provided explanations for the selection of the dynamic masking rate strategy and proposed a solution to the issue of a small dataset size.